 Al termine del precedente articolo abbiamo imparato a realizzare una registrazione digitale corretta, in cui tutti i suoni rientrano nel range dinamico permesso dai convertitori. Se avete fatto qualche prova di registrazione vi sarete sicuramente accorti che questo range, ovvero la differenza in volume tra il suono più basso e quello più alto registrabili è abbondante. Così tanto abbondante in verità da comportare alcuni inconvenienti nel momento dell’ascolto del materiale registrato.
Al termine del precedente articolo abbiamo imparato a realizzare una registrazione digitale corretta, in cui tutti i suoni rientrano nel range dinamico permesso dai convertitori. Se avete fatto qualche prova di registrazione vi sarete sicuramente accorti che questo range, ovvero la differenza in volume tra il suono più basso e quello più alto registrabili è abbondante. Così tanto abbondante in verità da comportare alcuni inconvenienti nel momento dell’ascolto del materiale registrato.
Nella registrazione e successiva riproduzione di un brano di musica classica avere un ampio range dinamico è oro colato. In questo genere di musica la differenza in volume tra diversi passaggi è un elemento fondamentale di espressione artistica, tanto che il poter conservare questa caratteristica all’interno di una registrazione è uno dei pregi che ha spinto l’adozione del CD da parte degli audiofili nei tardi anni 80.
In realtà l’ascolto di un brano caratterizzato da un ampio range dinamico presuppone un impianto stereo di ottima qualità in un ambiente acusticamente idoneo e soprattutto silenzioso. Provate ad ascoltare una sinfonia di Beethoven in autostrada o viaggiando in treno. Avete due possibilità: tenere il volume a un livello normale, sentendo bene i segmenti suonati ad alto volume e perdendo completamente nel rumore che vi circonda i pezzi più bassi, oppure alzare il volume abbastanza da riuscire ad ascoltare i pezzi più lievi sopra al rumore di fondo, rischiando però l’assordamento istantaneo nel momento in cui i tromboni cominciano il loro gaudioso fortissimo in fa maggiore. In realtà avete una terza possibilità: viaggiare con il dito sulla manopola del volume, alzandolo durante i passaggi più bassi, per poi abbassarlo al volo prima che l’onda d’urto dei tromboni di cui sopra vi sfondi il parabrezza. Vi è mai capitato? Complimenti, senza alcuna preparazione in materia di processazione del segnale sonoro, avete inventato la “compressione”!
Il termine corretto sarebbe “compressione dinamica” o ancora meglio “compressione del range dinamico”, ed è in soldoni un processo di manipolazione del suono che riduce la differenza tra i suoni più bassi e quelli più alti.
Questo processo è affidato a un componente, il compressore, che può essere hardware come software, e che opera riducendo i suoni al di sopra di una certa soglia (treshold) di una determinata quantità (ratio), esattamente come nell’esempio di cui sopra quando il volume dei tromboni supera una determinato valore (carico di rottura del parabrezza = treshold) voi abbassate il volume dell’autoradio con mezzo giro di manopola (ratio).
La compressione può essere utilizzata per scopi differenti, tutti utili ad un podcaster per cui in quest’articolo e nei prossimi vedremo di affrontarli tutti. Ma vediamo prima di tutto quelli che sono i parametri tipici di un compressore.
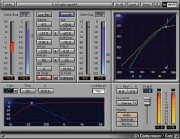
Ratio
La ratio è il rapporto tra l’intensità del suono in entrata e quello in uscita dal compressore. Immaginiamo di pronunciare due parole nel microfono con un volume diverso. Ad esempio “ma DAI”. Se “DAI” è pronunciato ad un volume dieci volte maggiore di “ma”, e la ratio del compressore è impostata su 2:1, la differenza di intensità tra i due suoni verrà dimezzata, quindi “DAI” uscirà solo cinque volte più forte di “ma”. Se la ratio è 5:1 “DAI” uscirà solo due volte più forte di “ma”.
Treshold
Non sempre è utile far funzionare il compressore su tutti i suoni in ingresso. Il parametro treshold serve proprio a indicare la soglia di intensità al di sotto della quale il suono non viene modificato dal compressore.
Attack time
Il tempo di attacco indica quanto tempo deve passare tra il momento in cui il suono supera il valore di “treshold” e quello in cui il compressore interviene abbassando il livello. Allungare il tempo di attacco serve a risparmiare i “transienti”. Wow che parolone! Cosa sono i transienti? In parole approssimative sono i primi millisecondi di un suono, e hanno alcune caratteristiche particolari: non sono armonici, e sono caratterizzati spesso da un contenuto in frequenze diverse dal resto del suono. Per alcuni strumenti musicali (un buon esempio è il rullante della batteria) è buona norma che la compressione risparmi i transienti per non appiattire il “carattere” del suono.
Release time
Il tempo di rilascio indica per quanto tempo, dopo che il suono è tornato sotto la treshold, il compressore deve continuare a tenere “abbassato” il volume. Un tempo di rilascio non immediato serve per evitare il famigerato effetto “pumping” che avviene, con tempi di rilascio troppo brevi, quando il segnale sorgente alterna rapidamente passaggi al di sopra e al di sotto della treshold. Per la compressione della voce parlata, con una treshold discretamente bassa per cui la voce stia quasi sempre al di sopra della soglia, un tempo di rilascio tra i 20ms e i 50ms dovrebbe essere un buon punto di partenza.
Make-up gain (e qui viene il bello)
Ricorderete dall’articolo dedicato al clipping che per evitare questo fastidioso fenomeno occorre impostare un volume di ingresso del segnale registrato sufficientemente basso affinché i segmenti più intensi della voce non superino la soglia della massima intensità registrabile nel dominio digitale (0dBFS). Abbiamo anche visto che in questo modo, mentre i passaggi ad alto volume non vengono “clippati” e sono ben udibili, quelli a basso volume risultano…. molto bassi, specialmente se il risultato finale viene ascoltato in ambiente rumoroso.
Bene, con la compressione abbiamo “schiacciato” tutto il nostro suono in modo che i passaggi più alti siano meno alti e in definitiva escano a un volume più vicino a quelli bassi (ricordate la ratio? diminuiamo di un rapporto 1:x la differenza tra un suono più alto e quello più basso). Ora con il make-up gain alziamo il volume di TUTTO QUANTO il nostro suono, sia quello dei passaggi più tenui che quello delle urla deliranti. Risultato: tutto il nostro parlato sarà più omogeneo e in grado di tenere testa ai rumori dell’ambiente di ascolto.
Lo so, è una procedura un po’ convoluta: prima schiacciamo tutti i suoni, poi li alziamo di nuovo, ma l’elaborazione del suono è così, un arte con tutte le sue procedure e formule magiche. Ricordatevelo così che è più semplice: prima abbassiamo tutto, ma abbassiamo molto di più i passaggi forti di quelli deboli, in modo da avere un sound omogeneo. Poi alziamo tutto quanto in maniera uguale in modo da portarlo in evidenza.
Ok, è un casino, forse è meglio che vi guardiate il video-tutorial qui sotto.
La compressione per podcasters from Franco Solerio on Vimeo.





